电池巨头掐架!宁德时代再起诉中创新航:索赔6100万元
快科技1月18日消息,日前,中创新航发布公告,近日收到福建省泉州市中级人民法院送达的民事起诉书,原告宁德时代新能源科技股...
科技
2 小时前
- 首页 > 新闻资讯 > routerz-loss模型的重要性
稀疏模型在深度学习领域发挥着越来越重要的作用。对于给定的token或样本,它可以只激活模型的一小部分,从而在拥有很大的参数量的同时也能做到计算友好。但是,如何可靠地训练这类模型依然是一个需要解决的问题。在这篇文章中,来自谷歌的BarretZoph、IrwanBello、WilliamFedus、JeffDean等研究者给出了一份「高效稀疏专家模型设计指南」。
稀疏专家神经网络展示了纯规模的优势,并为当今常用的静态神经网络架构提供了一种有效的替代方案。稀疏专家网络不是对所有输入应用相同的参数,而是为每个输入动态选择使用哪些参数。这允许网络极大地扩展参数的数量,同时保持每个token的FLOPs大致不变。这些方法的采用已经带来了SOTA翻译模型、4-7倍的预训练加速,以及仅使用1/3的训练成本就能达到GPT-3级的one-shot性能。尽管参数数量惊人,但稀疏模型将训练大型神经网络的碳足迹降低了一个数量级。然而,困难依然存在。
Fedusetal.(2021)观察到,与之前的SOTA方法(Raffeletal.,2019)相比,稀疏1.6T参数模型实现了4倍的预训练加速,但在SuperGLUE等常用基准上进行微调时,却落后于较小的模型。在Artetxeetal.(2021)中,研究者在域外数据上对MoE语言模型进行了微调,并观察到了相似的差距。
为了解决这一问题,Switch-XXL模型被提出,该模型参数较少,但计算占用空间增加到原来的8倍(FLOPs大约等于最大的T5模型),在自然语言理解任务上的性能有所提高。然而,必要的预训练受到先前在小规模研究中未检测到的训练不稳定性的阻碍。这些不稳定性后来在其他稀疏模型中被识别出来。这些结果揭示了参数和计算的必要平衡,但如何可靠地训练这种模型依然是一个待解决的问题。
这篇论文的目的就是提高稀疏模型的实用性和可靠性。他们研究了这两个问题,并给出了设计指南。最后,他们将稀疏模型的参数缩放到269B,其计算成本与32B密集编码器-解码器Transformer(稳定、可迁移的Mixture-of-Experts、ST-MoE-32B)相当。这是稀疏模型首次在迁移学习中实现SOTA性能,跨越了一系列不同的任务,包括推理(SuperGLUE、ARCEasy、ARCChallenge)、摘要(XSum、CNN-DM)、闭卷问答(WebQA、NaturalQuestions)和对抗式构造任务(Winogrande、ANLIR3)。
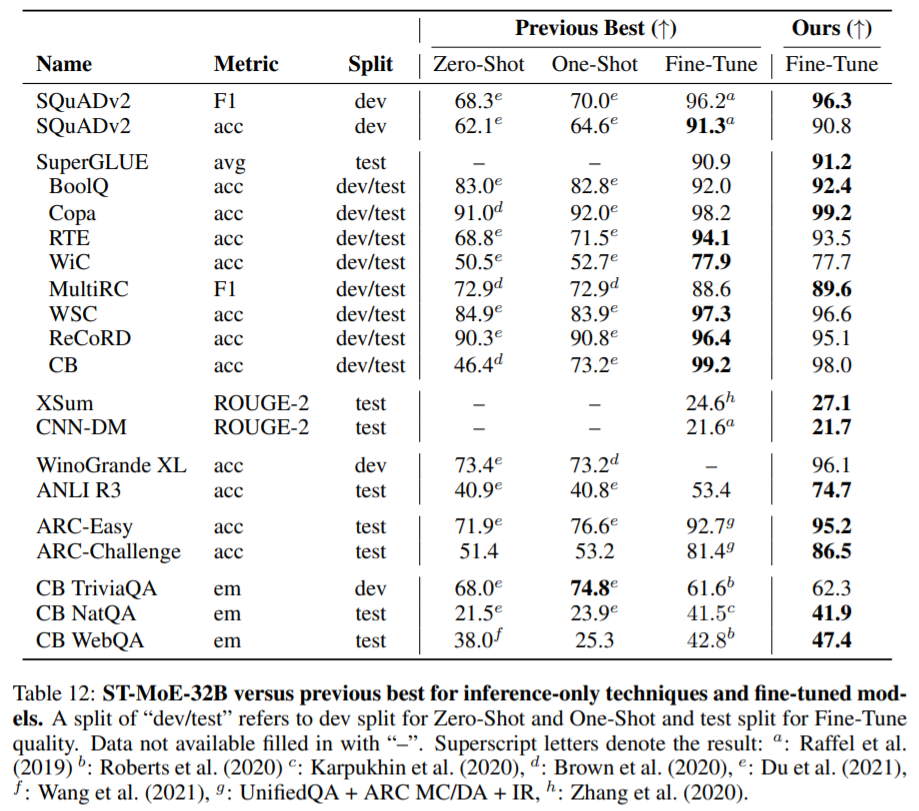
本文的贡献可以概括如下:
1、开展了一项关于稳定性技术的质量-稳定性权衡(quality-stabilitytrade-offs)大规模研究;
2、引入了routerz-loss来解决稳定性问题,同时略微提高了模型质量;
3、给出了关于稀疏和密集模型的微调分析,揭示了二者对批大小和学习率的不同超参数敏感性;他们发现,糟糕的超参数导致密集模型上几乎没有微调增益,尽管预训练有很大的加速;
4、给出了分布式环境下设计Pareto高效稀疏模型的架构、routing和模型设计原则;
5、给出了追踪跨专家层的tokenrouting决策的定性分析;
6、训练出了一个269B稀疏模型,在一组不同的自然语言基准上实现了SOTA性能。
routerz-loss
稳定神经网络最成功的方法之一是对激活的约束和梯度。一种流行的方法是在通过深度网络反向传播时,裁剪梯度范数来弥补爆炸梯度。
在这篇论文中,研究者使用Adafactor优化器是因为它的内存效率(尽管最近推出的8位优化器(Dettmersetal.,2021)可能会提供更好的trade-off)。Adafactor使用更新裁剪(updateclipping),而不是梯度裁剪(gradientclipping),其中对权重的更改被限制在一定的范数以下。他们尝试将更新裁剪收紧到更小的值。
接下来,他们研究了即将进入router的logit上的约束。router以float32计算专家的概率分布。然而,研究者发现,在最大的规模下,这不足以带来可靠的训练结果。为了解决这个问题,他们引入了routerz-loss,
其中,B是token的数目,N是专家数,x∈RB×N是将要进入router的logit。
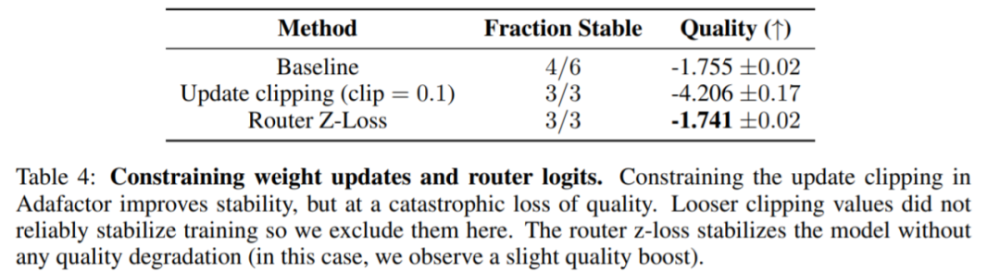
下表4显示,在三次运行中,updateclipping和routerz-loss都稳定了模型,但是updateclipping严重影响了模型的质量。因此,研究者使用z-loss方法来固定模型稳定性。
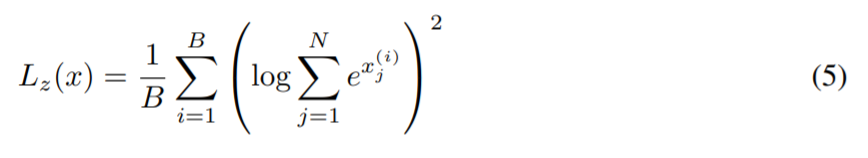
routerz-loss引入了另一个超参数(c_z),这是一个加权系数,作为优化的总损失的一部分。总损失是交叉熵损失(crossentropyloss,L_CE)、辅助负载平衡损失(auxiliaryloadbalanceloss,L_B)和routerz-loss(L_Z)的线性加权组合。
基于用超参数扫描进行预训练后的最佳模型质量,研究者选择c_z=0.001的值。附录B记录了预训练过程中的损失。
想查看更多微信群的小伙伴, 可以点击上面导航栏的微信群 或者下面按钮!
点我查看更多微信群
分享

快科技1月18日消息,日前,中创新航发布公告,近日收到福建省泉州市中级人民法院送达的民事起诉书,原告宁德时代新能源科技股...

蛇年将至,春节氛围渐浓。近日,郎酒在成都举办“红花郎春晚季 红红火火过春节——郎酒2024年度十大图片发布”活动,在活动...

1月17日9时,重庆特色伴手礼品牌认定进入点赞第一天。100个候选当日哪些品牌人气高?快手、上游新闻分别发布首日“龙虎榜...

本文转自:人民网人民网北京1月17日电 (记者孙博洋)记者从市场监管总局了解到,近日,国际标准化组织正式发布由我国牵头制...

在这辞旧迎新的美好时刻,我们即将迎来2025年春节,而今年,更是利唐i人事具有里程碑意义的一年——公司成立10周年。作为...

中新网1月17日电 据美国有线电视新闻网(CNN)报道,当地时间16日下午,美国SpaceX公司的“星舰”在得克萨斯州布...